0 Abstract
最近的许多论文都涉及到阅读理解,他们一般都包括(问题,段落,答案)元组。或许,一个模型必须综合问题和段落两者的信息来预测相应的答案。然而,尽管人们对这个话题产生了浓厚的兴趣,数百篇已发表的论文争夺排行榜的主导地位,但关于许多流行基准测试难度的基本问题仍未得到解答。在这篇论文中,我们为bAbI、SQuAD、CBT、CNN和Who-did-What的数据集建立了合理的基线,发现只考虑问题和只考虑段落的模型通常表现得出奇的好。在20个bAbI任务的14个中,只考虑文章的模型都能达到超过50%的准确率,有时能够达到完整模型的性能。有趣的是,尽管CBT提供了20个句子的故事,但只有最后一句是相对准确的预测所需要的。通过比较,SQuAD和CNN看起来更有实力。
1 Intoduction
目前,研究人员们提出了各种各样的端到端深度学习算法,以推动各种基准测试,阅读理解(RC)已经成为一项受欢迎的任务。以Hermann(2015);Onishi(2016)等人为代表的,不像之前的工作那样从一般的结构知识中处理问题答案。阅读理解需要从一个给定的无结构化的文章(段落)中抽取信息。不难想象,这样的系统该是何等的有用。与一般的文本摘要相比,阅读理解系统可以回答关于特定文档有目的性的问题,有效地提取事实和见解。
尽管多年来已经提出了许多阅读理解数据集(Hirschman 1999;Breck 2001;Penas 2011; Penas 2012;Sutcliffe 2013;Richardson 2013;Berant 2014;),最近,人们提出了更大的数据集,以适应深度学习的数据强度。这些语料库的来源和规模以及他们如何处理预测问题都不相同,这些问题主要有分类问题、跨度选择、句子检索或者开放式答案生成。研究人员在这些基准上稳步推进,提出了无数的神经网络架构,旨在利用问题和段落来产生答案。
在这篇论文中,我们认为,在经验基准的快速发展中,关键的步骤有时会被跳过。特别是,我们证明了其中一些任务的难度等级很低。例如,对于许多阅读理解数据集,无论是在介绍数据集的论文中,还是在那些提出模型的论文中,都没有给出在忽略问题或文章的情况下的表现如何。在其他数据集里,尽管文章可能包含了许多行文本,但也不清楚到底需要多少文本信息来回答这个问题。比如,答案可能总是出现在第一句或者最后一句。
我们对几个流行的阅读理解数据集和模型进行了介绍,并对它们的性能在只提供问题或只提供段落的情况下进行了分析。我们还展示了在许多任务中,在提供问题和段落的情况下。获得的结果出奇的好,超过了许多基线,有时甚至超过了相同的模型。
我们注意到类似的问题在Goyal的视觉问答和 Gururangan、 Poliak、Glockner的自然语言推理中显示出来。其他几篇论文也讨论了各种阅读理解基准测试的不足。我们将在下面介绍相应的数据集的段落中讨论这些研究。
2 Datasets
在下面的这部分中,我们将提供我们所调查的每个数据集的上下文,然后描述破坏数据的过程,这个数据是我们的只考虑问题和只考虑段落的实验所要求的数据。
CBT Hill(2016)通过使用儿童书籍中的文章。准备了一个cloze-style(填空式)阅读理解数据集。在他们的数据集中,每一篇文章包含了20个连续的句子,每个问题都是删除了一个单词的第21句。这个缺失的单词背当做答案。数据集被分为四类答案:命名实体,普通名词,动词和介词。训练语料包含了37000条数据,每个问题和10个答案对应,这些答案的词性和正确答案的词性相匹配。作者建立了基于lstm/词嵌入的只有问题的基线系统,但是没有展示他们使用只考虑问题或只考虑段落信息的最佳模型获得的结果。
CNN Hermann(2015)介绍了包含超过100万篇新闻文章,每一篇都有几个突出的句子。此外,他们还为填空式的数据集做准备,他们从一个突出句子(问题)中删除了一个实体(答案)。他们将所有实体匿名化,以确保模型依赖于文章中包含的信息,而不是通过例子来记忆给定实体的特征而忽略了文章。平均而言,文章包含26个实体,包括了全部可能的候选答案。Chen(2016)分析了CNN和Daily Mail任务的困难。他们为每个实体e(e在问题中出现,在文章中出现等等)手工设计了8个特性的集合,这展示了这个简单的分类器比许多早期的深度学习结果要好。
Who-did-What Onishi(2016)摘录了成对的新闻文章,每对都指向相同的事件。采用了填空式的方式,他们从一篇文章的第一句话(问题)中删除了一个人的名字(答案)。模型必须根据问题和这一对中的其他文章(段落)来预测答案。与CNN不同,Who-did-What不将实体匿名化。平均而言,每个问题和3.5个答案对应。作者从他们的数据集中删除了几个问题,以阻止一些简单的策略,比如总是预测在文章中出现最多(或第一次)的名字。
bAbI Weston(2016)提出了20个任务的集合,帮助研究人员识别和纠正他们的阅读理解系统的缺陷。与目前为止所讨论的数据集不同,这个任务中的问题不是填空式的,而是使用模板合生的。这限制了文章中出现短语的多样性,此外,这还将数据集词汇限制为150个单词,相比之下,CNN数据集的词汇量接近12万字。具有自适应记忆、ngrams语言模型和非线性匹配的记忆网络,在20个bAbI任务中的12个中得到了百分百的准确率。我们注意到Lee等人(2016)先前指出,bAbI的任务可能无法达到作为“AI完全问答”的一种衡量标准,提出了基于==张量积表示==的两种模型,这些模型在许多bAbI任务中达到了百分之百的精度。
SQuAD 最近,Rajpurkar等人发布了斯坦福问答数据集,这个数据集包含了10多万个众包问题,涉及536篇文章。每个问题都与从一篇文章中提取的段落相关联。这些段落比CNN和Who-did-What数据集中的段落更短。模型通过从这些段落中选择(可变长度的)答案。
Generating Corrupt Data 为了使问题或段落中的某些信息无效,但同时使每个架构保持完整,我们通过随机分配问题或者随机化段落,保留段落和答案之间的对应关系,来创建每个数据集的损坏版本。对于那些需要从文章中选择范围或候选答案的问答任务,我们创建的段落包含了随机位置的候选答案,但除此之外,还有一些随机的胡言乱语。
3 Models
在我们对各种阅读理解基线测试的调查中,我们依赖于以下三个最近提出的模型:key-value memory networks、gated attention readers和QA nets。尽管篇幅的限制阻碍了对每一个结构的全面讨论,但我们提供了对源文件的引用,并简要讨论了复现我们结果所必需的任何实现决策。
Key-Value Memory Networks 我们实现了一个Key-Value Memory Networks(KV-MemNet)(2016),并将它运用在bAbI和CBT两个数据集上。KV-MemNets是基于Memory Networks(Sukhbaatar 2015),在两个数据集上都表现良好。对于bAbI任务,键和值以及段落都被编码成词带模型。对于CBT任务,键是对候选答案周围5个单词窗口进行词带编码,值就是候选答案本身。我们将跳跃的数量固定到3,词嵌入大小调整为128。
Gated Attention Reader由Dhingra(2017)引入,Gated Attention Reader 像MemNets一样在段落中执行多个跳跃,单词表示在每一跳上都有改进,并被一个注意力集中模块映射到最后一跳的候选答案集上的概率分布。该模型几乎抵得上许多填空式的阅读理解数据集上的最佳报告结果,因此我们将它运用到Who-did-What,CNN,CBT-NE和CBT-CN。
QA Net最近由Yu等人引入。最近,QA-Net在SQuAD数据集上的表现优于所有以前的模型。段落和问题被作为输入给独立的编码器,这些编码器包括深度可分的卷积和全局自注意力机制。接下来是一个段落-问题的注意力层,然后是堆叠的编码器。这些编码器的输出被用来预测段落内的答案范围。
4 Experimental Results
bAbI tasks 表1展示了在bAbI任务中,取消在问题或段落中出现的信息后,Key-Value Memory Network所获得的结果。在任务2,7,13和20中,只有段落的模型在随机分配的问题中获得超过80%的准确率。此外,在任务3,13,16和20中,只有段落的模型与在全数据集上训练的模型的性能相当。在任务18中,只有问题的模型的准确率达到了91%,几乎与全模型所取得的93%的最佳性能相当。这些结果表明,一些bAbI的任务比人们想象的要容易。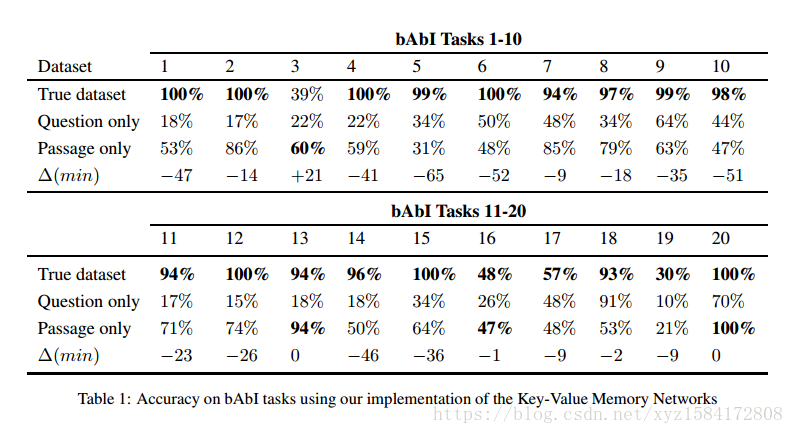
Children’s Books Test 在NE和CN CBT任务中,只有问题的模型在KV-MemNets上获得的精度接近于完全准确,在动词(V)和介词(P)任务中,只有问题的模型优于完整的模型(表2)。只有问题的模型在Gated attention readers上的命名实体(NE)和普通名词(CN)任务分别达到了50.6%和54%的准确率,而只有段落模型的精确度分别为40.8%和36.7%。我们注意到,在Hill等人(2016)的NE任务中报道的19个结果中,我们使用问题模型信息的结果可以超过16个。表3显示,如果我们只使用最后一句话而不是使用文章中的全部20句话,我们基于KV-MemNet的句子记忆实现了比在大多数子任务上的完整模型更好或相当的性能。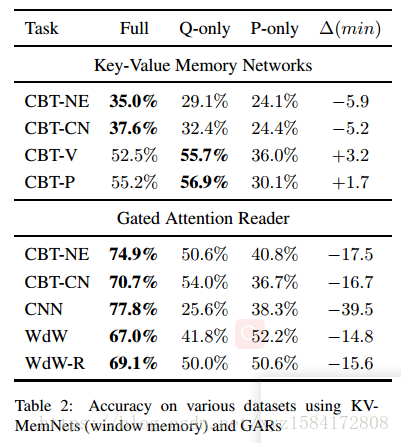
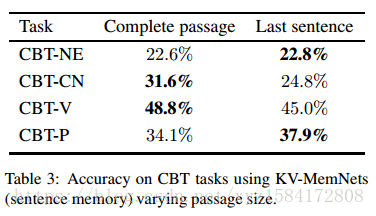
CNN 表格2展示了Gated Attention Reader在CNN数据集上的性能。只有问题模型和只有段落模型分别获得了25.6%和38.3%的精确度,而真正的数据集则是77.8%。这种精确性的下降可能是由于实体的匿名化,这些匿名化的实体阻止了模型构建实体的特定信息。尽管Chen等人提出了其缺陷,我们发现,对于CNN和我们评估的所有填空式的阅读理解数据集,似乎都是最精心设计的。
Who-did-What 在严格和放松的环境下,只有段落的模型能达到超过50%的准确率,在严格的环境中达到完全模型的15%。只有问题的模型在放松环境中也达到了50%的准确率,同时在严格的环境中达到了41.8%的准确率。我们的只有段落的模型也比Onishi等人(2016)报告的所有被抑制的基线和5个额外基线的性能都要高。我们怀疑这些模型会记住特定实体的属性,从而证明赫尔曼等人(2015)使用的实体匿名化来构建CNN数据集。
SQuAD 我们的研究结果表明,SQuAD是一项异常精心设计和具有挑战性的阅读理解任务。答案的范围选择模式要求模型考虑段落,因此Q-only在QANet上展现出了糟糕性能(表4)。由于SQuAD需要通过范围选择来回答,所以我们在这里构造只有问题模型的变体:通过随机排列所有相关问题的答案,用随机的单词填满空白。此外,Q-only型和P-only模型的F1得分分别仅为4%和14.8%(表4),明显低于正常任务的79.1。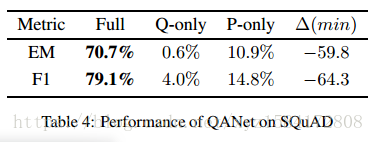
5 Discussion
我们简要地讨论了我们的发现,为评估新的基准和算法提供了一些指导原则,并推测为什么有些问题可能已经被忽视了。我们的目标不是责怪过去数据集的创造者,而是为未来的研究人员通过提供实用的指导来支持社区。
Provide rigorous RC baselines 公开的阅读理解数据集应该包含合理的基线,以描述任务的难度,特别是问题和段落的重要性。此外,改进的后续报告应该展示在全部任务和不涉及问题和段落的变化方面的表现。尽管许多技术创新据说是通过更好地匹配问题和段落中的信息来工作的,但如果没有这些基线,人们就无法判断结果是否来自于声称的原因,或者模型是否能更好地完成段落分类工作(不考虑问题)。
Test that full context is essential 即使在需要问题和段落的任务中,问题也可能比实际情况更困难。乍一看,CBT中长度为20的段落,可能表明需要对所有20句话进行推理,以确定每个问题的正确答案。然而,事实证明,对于某些模型,可以通过只考虑最后一句话来达到类似的性能。我们建议研究人员提供合理的==消融==,以描述每个模型真正需要的上下文的数量。
Caution with cloze-style RC datasets 我们注意到,填空式数据集通常是由编程的方式创建的。因此,可以将数据集生成、发布和合并到许多下游研究中,而这些研究都没有人工检查数据的时间。我们推测,结果是这些数据集往往不太考虑回答这些问题所涉及的内容因此特别容易受到我们研究中所描述的那些被忽视的弱点影响。
A note on publishing incentives 我们担心推荐的实验严密性可能会与当前的公开激励措施相违背。我们推测,引入数据集的论文,通过省略不愉快的数据消融,而不是把它们包括在内,或许更有可能在会议上被接受。此外,由于评审者常常要求结构新颖,通过提供未经证实的故事来解释为什么一个给定的体系结构起作用的原因,,而不是提供严格的消融研究来排除虚假的解释和不必要的模型组件,方法类论文可能会找到更容易接受的途径。为了更广泛地讨论机器学习研究中的偏差激励和经验严密性,我们将感兴趣的读者指向 Lipton and Steinhardt (2018) and Sculley et al.(2018)
题外话
之前看论文,也没怎么记录,导致很多时候看了没过多久,基本上也就忘得差不多了。于是今后考虑以论文翻译,论文笔记或者复现论文中模型的方式巩固从而加深印象。
这是翻译的第一篇,本渣也是一个英语渣,有很多单词翻译都拿不太准(某些专业词汇还不能很好的翻译,所以在文中也用黄色阴影来标注出来)。
还是回到这篇论文上来,这篇论文是EMNLP2018的最佳短论文,其中首先介绍了阅读理解常用的数据集以及比较流行的网络模型,通过对这些的介绍,引入了本文的主要工作。在具体实验中,利用更简单的实验模型却能达到相当的结果,进而引入本文的主题——阅读理解真正读到了多少?缺少基线对数据集的测试,就不能真正了解到那部分数据是有用的,那部分数据是无用的,而且数据集往往都是为了某个实验而精心设计的。文中最后给出了一些指导建议(划重点),这些建议一阵见血的指出了目前学术界的问题,这些大家一看就懂,自行体会。